Semantic Segmentation for Self-Driving Cars
Semantic segmentation
최근 몇 년 동안 자동차 주변을 식별할 수 있는 수많은 기술이 등장했습니다. 우리 주변의 장면을 이해하는 것은, 주변의 지리적 모양과 더불어 주변에 있는 물체를 분석하기 위한 중요한 분야입니다.

이미 알고 있듯이 자율 주행 시스템의 첫 번째 단계는 객체 인식, 객체 위치 파악 및 의미 세분화를 기반으로 합니다.
시맨틱 분할은 주어진 시맨틱 클래스에 속하는 이미지의 각 픽셀에 레이블을 지정합니다. 일반적으로 이러한 클래스는 거리, 교통 표지판,
거리 표시, 자동차, 보행자 또는 인도일 수 있습니다.
시맨틱 분할은 위해 딥러닝을 배포 할 때 사람이나 차량과 같은 이미지의 주요 객체 인식은 더 높은 수준의 신경망에서 수행됩니다.
전략의 가장 큰 이점은 픽셸픽셀 수준에서 약간의 차이가 식별에 영향을 미치지 않는다는 것입니다. Semantic segmentation에는 일반적으로 하위 계층에서만 발생하는 작은 특징의 픽셀 단위로 정확하게 분류해야 합니다.
Introduction to semantic segmentation
최근 몇 년 동안 자동차 주변을 식별하도록 설계된 수많은 기술 시스템이 등장했습니다. 우리 주변의 장면을 이해하는 것은 장면의 기하학과 주변의 관련 물체를 분석하기 위한 중요한 연구 영역으로 밝혀졌습니다. CNN은 이미지 분류, 객체 감지 및 의미 체계 분할에서 가장 효과적인 비전 컴퓨팅 도구로 입증되었습니다. 자동화된 환경에서는 픽셸 수준에서 주변의 주어진 장면을 이해하기 위해 몇 가지 중요한 결정을 내리는 것이 중요합니다. 시맨틱 분할은 이미지의 개별 픽셸에 레이블을 할당하는 가장 효과적인 방법 중 하나임이 입증되었습니다.
최근 운전 보조 시스템은 운전 경험을 향상할 수 있는 다양한 기회를 제공하기 때문에 최고의 연구 분야가되었습니다.ADAS(Advanced Driving Assistance System)에서 사용할 수 있는 시맨틱 분할 기술을 사용하여 운전자 성능을 향상시킬 수 있습니다.
Semantic segmentation은 이미지와 각 픽셀을 클래스 레이블과 연결하는 프로세스입니다. 여기서 클래스는 사람, 거리, 도로, 하늘, 바다 또는 자동차 일 수 있습니다.
Pre-trained models for semantic segmentation(시맨틱 분할을 위한 사전 훈련된 모델)

U-Net
U-Net은 2015년 국제 생물 의학 영상 심포지엄(ISBI)에서 물린 방사선 촬영에서 컴퓨터 자동 충치 감지를 위한 가장 도덕 전이 그랜드 챌린지 상을 수상했으면 2015년 ISBI에서 세포 추적 챌린지에서도 우승했습니다.
U-Net의 기본 아이디어는 업 샘플링 연산자가 풀링 작업을 대체하는 일반 네트워크에 연속 레이어를 추가하는 것입니다. 이로 인해 U-Net의 레이어는 출력의 해상도를 높입니다.
SegNet
SegNet은 Computer Vision and Robotics Group
(http://mi.eng.cam.ac.uk/Main/CVR)의 구성원이 연구하고 개발 한 멀티 클래스 픽셀 단위 분할을 위한 심층 인코더-디코더 아키텍처입니다.
SegNet 아키텍처는 인코더 네트워크, 해당 리코더 네트워크 및 최종 분류 픽셸 단위 계층으로 구성됩니다.

Encoder
VGG-16에서 13개의 컨벌루션 레이어를 가져오는 인코더에서 킨볼 루션 및 최대 풀링이 수행됩니다. 해당 최대 풀링 인덱스는 2X2 최대 풀링을 수행하는 동안 저장됩니다.
Decoder
업 샘플링 및 컨볼루션은 디코더의 소프트 맥스 분류가에서 각 픽셀의 끝에서 수행됩니다. 해당 인코더 계층의 최대 풀링 인덱스는 업 샘플링 프로세스 중에 호출되고 업 샘플링됩니다. 그런 다음 K클래스 소프트 맥스 분류기를 사용하여 각 픽셸을 예측합니다.
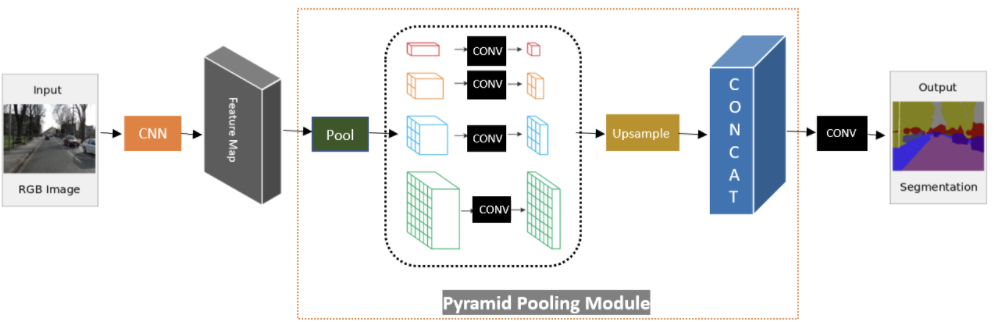
PSPNet
주어진 입력 이미지에 대해 컨벌루션 신경망을 사용하여 특징 맵이 추출됩니다. 그런 다음 피라미드 구문 분석 모듈을 사용하여 하위 영역의 다양한 표현을 수집합니다. 그다음에는 업 샘플링 및 연결 레이어를 통해 로컬 및 글로벌 콘텍스트 정보를 모두 포함하는 피쳐의 최종 표현을 형성합니다. 마지막으로, 이전 레이어의 출력이 convolution 레이어에 입력되어 픽셸 당 최종 예측을 얻습니다.
DeepLabv3+
DeepLab은 시맨틱 분할 최첨단 모델입니다. 2016년에 Google에서 개발하고 오픈 소스 했습니다. 여러 버전이 출시되었으며 그 이후로 모델이 많이 개선되었습니다. 여기에는 DeepLab V2, DeepLab V3 및 DeepLab V3+ 가 포함됩니다.
DeepLab V3+ 가 출시되기 전에는 필터와 전에는 필터와 풀링 작업을 사용하여 다양한 속도로 다중 규모 상황 정보를 인코딩할 수 있었습니다. 새로운 네트워크는 공간 정보를 복구하여 더 날카로운 경계로 물체를 캡처할 수 있습니다. DeepLabv3 +는 이 두 가지 접근 방식을 결합합니다. 인코더-디코더와 공간 피라미드 풀링 모듈을 모두 사용합니다.

앞장 설명
인코더 : 인코더 단계에서는 사전 훈련된 컨벌루션 신경망을 사용하여 입력 이미지에서 필수 정보를 추출합니다. 분할 작업에 대한 필수 정보는 이미지에 있는 개체와 해당 위치입니다.
디코더: 인코더 프로세스에서 추출된 정보는 원본 입력 이미지의 크기와 동일한 출력을 만드는 데 사용됩니다.
E-Net
실시간 픽셀 단위 시맨틱 분할은 SDC를 위한 시맨틱 분할의 훌룡한 응용 프로그램 중 하나입니다. 정확도는 SDC에서 증가 할 수 있지만 시맨틱 분할을 배치하는 것은 여전히 어려운일입니다. 이 섹션에서는 정확도를 높이면서 저전력 모바일 장치에서 실행하는 것을 목표로 하는 효율적인 신경망 (E-Net)을 살펴 보겠습니다.
E-Net은 실시간 픽셸 단위 시맨틱 분할을 수행할 수 있는 기능으로 인해 널리 사용되는 네트워크입니다. E-Net은 U-Net 및 SegNet과 같은 기존 모델보다 최대 18배 더 빠르며 FLOP가 75배 적으며 매개 변수가 79배 적어 정확도가 훨씬 더 높습니다. E-Net 네트워크는 인기 있는 CamVid, Cityscapes 및 SUN 데이터 세트에서 테스트됩니다.


E-Net을 사용하여 시맨틱 분할을 구현합니다. 이미지와 비디오에서 다양한 물체를 감지하는 데 사용합니다.
Semantic Segmentation using E-Net
딥 러닝은 컴퓨터 비전 분야, 특히 물체 감지 분야에서 뛰어난 정확성을 제공했습니다. 기존 프로세스의 주된 문제는 알고리즘이 이미지의 일부를 인식할 수 없다는 것입니다.
반면 시멘틱 세그멘테이션 알고리즘은, 이미지를 관련 범주로 나누는 것을 목표로 합니다. 입력 이미지의 모든 픽셀을 사람,나무,거리,도로,자동차,버스 등 클래스 레이블과 연결합니다.시맨틱 분할 알고리즘은 동적이며 자율 주행 자동차(SDC)를 포함하여 많은 사용 사례가 있습니다.
OpenCV, 딥 러닝 및 ENet 아키텍처를 사용하여 이미지와 비디오 시맨틱 분할을 수행하는 방법을 배웁니다.
Enet(Efficient Neural Network)
Enet(Efficient Neural Network)은 실시간 픽셸 단위 시맨틱 분할을 수행할 수 있는 능력으로 인해 널리 사용되는 네트워크 중 하나입니다. ENet은 최대 18배 더 빠르고, FLOP가 75배 더 적으며, 다른 네트워크보다 매개 변수가 79배 더 적습니다. 이는 ENet이 U-Net 및 SegNet과 같은 기존 모델보다 더 나은 정확도를 제공함을 의미합니다. ENet 네트워크는 일반적으로 CamVid, CityScapes 및 SUN 데이터 세트에서 테스트됩니다. 모델의 크기는 3.2MB입니다.

OpenCV DNN 모듈 사용하기
https://deep-learning-study.tistory.com/299
[OpenCV 딥러닝] 미리 학습된 파일을 OpenCV DNN 모듈로 딥러닝 실행하기 - cv2.dnn.readNet
OpenCV DNN(Deep Neural Network) 모듈 미리 학습된 딥러닝 파일을 OpenCV DNN 모듈로 실행할 수 있습니다. 순전파(foward), 추론(inference)만 가능하며 학습은 지원하지 않습니다. 1. 네트워크 불러오기 - c..
deep-learning-study.tistory.com
링크 안에 코드와 설명이 있습니다
blob 사용하기
이 #Blob라는 것은 동일한 방식으로 전처리된 동일한 너비, 높이 및 채널 수를 가진 하나 이상의 이미지 말합니다.
추론 엔진의 워크 플로우를 돌려보고 blobFromImage가 어디 위치로 들어가는지 알아봅시다.

4D Tensor(NCHW)
이 함수의 출력 값은 4차원 텐서입니다. 여기서 N은 이미지의 수입니다. C는 채널 수, H는 텐서의 높이, W는 텐서의 너비를 나타냅니다.
값들은 blob 객체에 저장된 다음, 이미지 또는 비디오 추론을 얻을 수 있는 훈련된 모델로 전달합니다.